Database Connectivity
Database Neutral
At its core, Servoy is a comprehensive platform to develop database-driven applications. As such, Servoy allows developers to connect to any standard Relational Database Management System (RDBMS). To achieve this, Servoy employs Java Database Connectivity (JDBC) technology. JDBC is a connectivity standard that allows Java-based applications to interact transparently with any database vendor that provides a compliant driver.
Servoy's Query Engine
The Servoy platform uses Structured Query Language (SQL), a standard communications protocol to issue requests to databases. The traditional development of database applications typically requires advanced SQL knowledge to adequately and efficiently retrieve data. Moreover, database vendors often adapt their own "flavors" of SQL, making database portability an issue. If an application uses non-standard SQL expressions, it cannot be easily deployed against databases other the the one for which it was developed.
The Servoy platform completely obviates the need for developers to write their own SQL. Instead Servoy dynamically generates all the SQL required to read and write data for all but the most complex scenarios. Servoy's generated queries are guaranteed to be optimized and database-neutral. At the same time, the Servoy platform is open and allows developers with the knowledge and preference for writing SQL to do so as well.
Named Connections
Developers will specify a Server Name, which maps to a specific database connection configuration (i.e. user, password, URL, etc). At run time, Servoy will automatically create a pool of connections for a given Server Name, which will be reused for the duration of the application server up time. Developers are always insulated from the complexities of connecting to the database.
The details of a connection configuration are stored as part of the development or deployment environment and are never part of the code base. This allows the database connection to be changed for a given context without making modifications to an application's code base.
For example, it is common to have separate databases for development/testing and production. Therefore, a Server Name could resolve to a test database in both Servoy Developer and an instance of Servoy Server used for staging. The same Server Name would resolve to a production database for an instance of Server Server used in production. Another example is for multiple, on-premise, deployments where local instances of Servoy Server rely on local database connections.
Switching Connections
While database connections can be changed transparently between different development and deployment contexts, they can also be changed within the same context. Servoy's API provides a means for developers to change, at run time, from one Server Name to another. For example, different application user groups may be required to use different connections to the same database. In another example, different customers may have their data stored in their own separate database. In both these cases, a specific Server Name is identified and used for an individual client session.
Connection Pooling
Servoy uses database connection pooling technology which provides significant benefits in terms of application performance, concurrency and scalability. Database connections are often expensive to create because of the overhead of establishing a network connection and initializing a database connection session in the back end database. Moreover, the ongoing management of all of a database's connection sessions can impose a major limiting factor on the scalability of an application. Valuable database resources such as locks, memory, cursors, transaction logs, statement handles and temporary tables all tend to increase based on the number of concurrent connection sessions. This limitation is overcome using Connection Pooling, whereby a limited number of connections is shared by a larger number of clients. When a client makes a new request for data, the application server briefly borrows a connection from the pool to issue the query, then returns it to the pool. In this manner an application can scale well beyond the limits of the database without compromising performance. Servoy's connection pools are configurable so that connectivity can be optimized to suit applications of various sizes.
Dynamic Data Binding
The Servoy platform provides a Graphical User Interface (GUI), as well as an Application Program Interface (API) which dynamically bind to database resources. This means the Servoy Application Server will dynamically generate and issue the SQL required to Read, Insert, Update and Delete database records in response to both the actions of the user and the behest of the developer.
In the simplest example, a user navigates to a form (which is bound to a specific database table) showing customer data. When the form shows, the Servoy Application Server issues a SQL select statement on the customer database table, retrieves the results of the query and displays them in the form.
When a user types a value into a text field (which is bound to a specific column of the database table) and clicks out, the Servoy Application Server issues a SQL update command to the database to modify the selected record. The resulting change is also broadcast|display/DOCS/Data+Broadcasting|||\ to all connected clients.
In another example a user may click a button, initiating a script written by a developer using Servoy's data API, a high-level abstraction to perform low-level database operations. The developer need only write code to interact with the API. The Servoy Application Server will translate the instructions into the raw SQL needed to perform the action.
The fundamental unit of data binding in both the GUI and the API is the Servoy Foundset|display/DOCS/Foundsets+Concepts|||\ object.
Client Cache
A Servoy client instance keeps track of which database records are in use. This is called the Client Cache and it optimizes performance by reducing the number of queries made to the database. Records are tracked by primary key. The first time the contents of a record are accessed, the Application Server must issue a query to the database on behalf of the client. The values for all of the columns of the record object are held in memory and therefore, subsequent access of the record will not produce anymore queries to the database. The user experience is greatly enhanced as one can browse quickly between forms and among cached records.
A record may fall out of the cache gracefully to conserve memory and is automatically reloaded the next time it is accessed. This happens at the discretion of the client's caching engine, which is highly optimized. Relieved of the burden of managing memory, the developer can focus on more important things.
Data Broadcasting
What happens to the cache when the contents of a record are changed independent of an individual client session?
Fortunately, the Servoy Application Server issues a Data Broadcast event to all clients whenever a record is inserted, updated or deleted by another Servoy Client. This notification allows each client to automatically update its cache providing the end users a shared, real-time view of the data.
In a simple example, two remote users are looking at the same customer record. The first user modifies the customer's name and commits the change. The second user immediately see's the change updated in his/her client session.
This functionality is provided by default for all Servoy client types. There is nothing that a developer needs to do to enable it. However, the developer may augment the default functionality by capturing the data broadcast event and invoking specific business logic. Also, Servoy's API provides a means to programmatically update client caches in cases where a record is modified outside of any Servoy Client session, i.e. from another application.
Data Transactions in Servoy
Data manipulations in Servoy happen inside an in-memory transaction. When a record is created or modified, either by user action or by developer, nothing is committed to the database immediately. The Servoy Client tracks all newly-created and modified records, including which columns have changed, their former and latter values. As records are added or modified, the amount of information stored in the In-Memory transaction accrue until they are committed or rolled back. The duration of this In-Memory transaction can be short or long depending on the client's configurable Auto Save setting.
Auto Save: ON
By default, every Servoy client is started with the Auto Save setting initialized to on/true. This means that the In-Memory transaction is typically very short as changes are committed automatically as the user navigates the client session. Specific actions like clicking in a form's area, navigating to a different form, clicking a button, etc. all trigger a save event. Auto Save is ideal for situations where the user is intended to be able to make edits freely.
Auto Save: OFF
The developer may optionally set the Auto Save setting to off/false. This means that the length of the In-Memory transaction is controlled by the developer. As changes accrue, they are never committed until the developer programmatically invokes a save event. It is ideal to disable Auto Save for scenarios where the user is intended to perform edits in a controlled situation where a group of edits may be saved or rolled back all together.
The Auto Save setting can be programmatically changed throughout the duration of the client session to accommodate different modes for different editing scenarios.
The Anatomy of the In-Memory Transaction
Servoy provides a robust data API, giving the developer full access to the In-Memory transaction, which consists of a listing of all record objects that were added or modified. For each of these record objects, there is a listing of every column whose value was changed. For every modified column, there is a reference to the value before and after the edit. The transaction API also allows developers to distinguish between records that are newly-created and do not yet exist in the database, versus records that already exist in the database, but have outstanding edits.
Saving Data Changes
A developer can programmatically issue a save event, causing the contents of the In-Memory transaction to be automatically translated into instructions to insert/update database tables. A developer can optionally invoke a save event for a specific record only, leaving the rest of the transaction unaffected.
If for some reason one or more records were unable to be saved (i.e. due to a back-end database violation, etc.), the transaction will also keep track of Failed Records and their associated errors.
Rolling Back Data Changes
A developer can programmatically issue a command to rollback the contents of the entire In-Memory transaction, causing newly created records to be removed and modified records to be reverted to their state prior to the start of the In-Memory transaction. The developer can optionally choose to rollback changes for a specific record, leaving the rest of the transaction unaffected.
What about Deleting Records?
It is important to note that record deletes are not part of the In-Memory transaction. When a record is deleted, the instructions are sent to the database immediately and the delete cannot be rolled back.
The Servoy Foundset
The Servoy Foundset is a developer's window into Servoy's Data Binding layer. A single foundset always maps to a single database table and is responsible for reading from and writing to that table. From the user interface, a foundset controls which records are loaded and displayed, as well as how records are created, edited and deleted. From the developer's perspective, a foundset is a programmable object with specific behaviors and run-time properties that provide a high-level abstraction to facilitate low-level data operations.
Forms Bound to a Foundset
A Servoy Form is typically bound to a single database table and the form will always contain a single Foundset object which is bound to the same table. Much of the action in the user interface, such as a user editing data fields, directly affects the form's foundset. Conversely, actions taken on the foundset, such as programmatically editing data, is immediately reflected in the form.
While a form is always bound to a foundset, a foundset may be used by 0 or more forms. Foundsets can be created and used by a programmer to accomplish many tasks.
Often, there can be several different forms which are bound to the same table. In most cases the forms will share the same foundset and thus provide a unified view. For example, imagine a form showing a list of customer records, where clicking on one of the records switches to another form showing a detailed view of only the selected record. The forms will automatically stay in sync and there is no need to coerce the forms to show the same record. Exceptions to this behavior include scenarios where forms are shown through different Relations, or have been explicitly marked to use a separate foundset.
Loading Records
One of the primary jobs of a Foundset is to load records from the table to which it is bound. A Foundset object is always based on an underlying SQL query, which may change often during the lifetime of the Foundset. However the query will always take the form of selecting the Primary Key columns from the table and will also always include an Order By clause, which in its simplest form will sort the results based on the Primary Key columns.
Foundset Loading
SELECT customerid FROM customers ORDER BY customerid ASC
After retrieving the results for Primary Key data, the Foundset will issue subsequent SQL queries to load the matching record data in smaller, optimized blocks. This query happens automatically in an on-demand fashion to satisfy the Foundset's scrollable interface.
Example: Record loading query
SELECT * FROM customers WHERE customerid IN (?,?,?,?,?,?,?,?)
Scrolling Result Set
The Foundset maintains a scrollable interface for traversing record data. This interface includes a numeric index for every record that is returned by the Foundset's query.
Foundset Size
The Foundset also has a Size property, which indicates the number of records that are indexed by the Foundset at any given time. Because the Foundset's SQL query may eventually return thousands or millions of results, the initial size of the Foundset has a maximum of 200. This value can grow dynamically, in blocks of 200, as the Foundset is traversed.
Selected Index
The Foundset maintains a Selected Index, a cursor with which to step through the records. If the selected index equals or exceeds the size of the Foundset, the Foundset will automatically issue another query to load the next batch of primary key data. Thus the Foundset loads record data and grows dynamically with the changing Selected Index property.
Example dynamic Foundset size
// Foundset size grows dynamically as the Foundset is traversed foundset.getSize(); // returns 200 foundset.setSelectedIndex(200); foundset.getSize(); // returns 400
Related Foundsets
Foundsets are often constrained or filtered by a Relation. In this situation, the foundset is said to be a Related Foundset and its default SQL query will include in its Where Clause, the parameters by which to constrain the foundset.
It is important to make the distinction that a relation and a foundset are not one in the same. Rather, a relation name is used to reference a specific foundset object within a given context. The context for a related foundset is always a specific record object. But for convenience, related foundsets may be referenced within a form's scripting scope and as a property of any foundset. However in these cases, the context is always implied to be the selected record in the context.
For example:
Take a predefined Relation, customers_to_orders, which models a one-to-many relationship between a customers table and an orders table. The following three lines of code, executed within the scripting scope of a form based on the customers table, all produce the same result.
// Returns the number of orders for the selected customer record in this form's foundset customers_to_orders.getSize(); // ...the same as: foundset.customers_to_orders.getSize(); // ...also the same as: foundset.getSelectedRecord().customers_to_orders.getSize();
Related foundsets can be chained together using relation names. Again, the shorthand implies the context of the selected record for each foundset.
For Example:
// Returns the number of order details for the selected order record of the selected customer: customers_to_orders.orders_to_order_details.getSize(); // ...is the same as: customers_to_orders.getSelectedRecord().orders_to_order_details.getSelectedRecord().getSize();
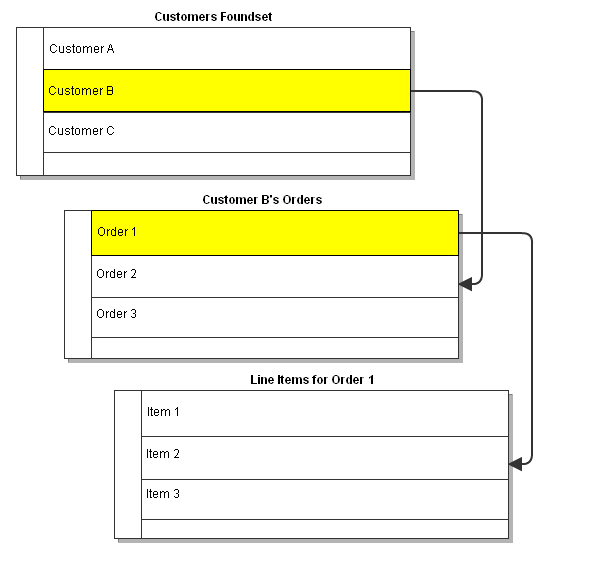
Foundsets and Data Broadcasting
A Foundset may be automatically updated when the client receives a Data Broadcast Event. If the data change affected the table to which the foundset is bound, the foundset will be refreshed to reflect the change.
Question from Patrick Talbot that this chapter could answer
I remember I was thinking that there were some gray areas when it comes to datasets and foundsets, and generally how Servoy is generating the SQL from these depending on relations etc. I noticed that there were often questions about that in the forum, and no definitive answers of course (but at least pointers to what approach gives you what), and in my company too, people are coming to me quite often with some of the following questions:
- the 200 records loaded in a batch, and how to treat it correctly
- databaseManager.loadRecords() different flavors and what it does exactly
- how Servoy is treating DB Views (no refreshing, need to manually add the PK(s))
- calculations and aggregations and how/why they will deteriorate performances (what is the SQL involved especially in case of table/list forms)
- about dataBroadcast, how they act on foundsets but not datasets (nor foundsets based on views)
- dataBroadcast again: how to refresh you client's data after a batch (processor) update (maybe demonstrate the new headless_client plugin?)
- how to use the JSFoundsetUpdater properly, and how to efficiently update a whole foundset in one go
- the use of databaseManager.setCreateEmptyFormFoundsets() and what it means
- the advantage of using valueLists instead of relations to display related data in table/list forms
- how/why Servoy is sometimes creating temporary table to perform some joins
- generally how to interpret the performance tab in the server admin
Seems like a lot of topics in one, really, but of course not necessarily all of these topics need to be addressed, or addressed at the same time, but I really think that these are things that need more explanations/clarifications/demonstrations.
Some stuff on convertors
[] Paul: hey
[] Paul: Ff een Q:
[] Paul: Als je met modules werkt, dan kunnen meedrere modules een tableevetn gedefinieerd hebben. die worden allemaal aangeroepen, toch, maar in een willekeurige volgorde, correct?
[] Paul: En tweede Q: hoe zit dat met column level stuff? Da's nooit solution specifiek? dus als je een global method converter aned aan een column, dan met er gewoon een method met die naam in de solution zitten, anders wordt ie geignored, of krijg je dan een exception?
[] Jan Blok: 1) klopt
[] Jan Blok: 2) de method moet bestaan ja, zo niet ignore
[] Paul: hey
[] Paul: Ff een Q:
[] Paul: Als je met modules werkt, dan kunnen meedrere modules een tableevetn gedefinieerd hebben. die worden allemaal aangeroepen, toch, maar in een willekeurige volgorde, correct?
[] Paul: En tweede Q: hoe zit dat met column level stuff? Da's nooit solution specifiek? dus als je een global method converter aned aan een column, dan met er gewoon een method met die naam in de solution zitten, anders wordt ie geignored, of krijg je dan een exception?
[] Jan Blok: 1) klopt
[] Jan Blok: 2) de method moet bestaan ja, zo niet ignore
Overview
Content Tools
Activity